1、功能介绍
单因素分析:是指在一个时间点上,研究不同水平的某因素对一个独立变量的影响程度的分析。即实验处理仅为一个方向,如研究不同药物对病例状态恢复的影响等。
多因素分析:是对一个独立变量是否受一个或多个因素或变量影响而进行的分析。
一般情况下,进行建模之前使用单因素或者多因素分析,可以初步探究因变量与自变量之间的关系,再做下一步计算。但是,我们在做分析时有可能遇到这种情况,例如:某个变量单因素分析显著,但是多因素分析又不显著影响,这时候该怎么办呢?别担心,下面这个表格带你分析这几种案例。
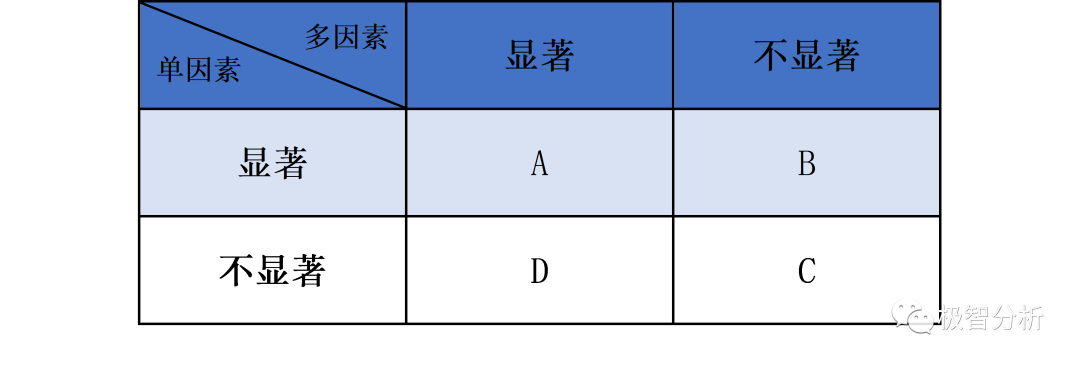
对于一个因素,做完单因素和多因素分析后有四种情况,当单因素和多因素分析结果相同时,很好判断是否纳入到接下来的模型。 但是出现B、D这种相互矛盾的情况该怎么处理?对于这两种情况,都有相应的解释:
1.1 B情况
单因素结果表明有显著影响但是多因素表明没有影响:一般是由于混杂因素对这种因素的作用进行了掩盖,在多因素分析中,这种混杂因素的作用被减弱,因素的影响又变得显著,比如研究教育程度和是否应届生对工资的影响。
解决办法:对这些变量进行PSM倾向性匹配处理,或者扩大样本量都是比较好的解决办法。比如你想研究施加某种干预对结局指标是否有改善,数据来自回顾性的既有资料的收集,由于是观察性研究,大概率存在混杂因素在组间不均衡的问题(如基线不平),这个时候你就可以考虑倾向性得分分析了
1.2 D情况
单因素结果表明不显著影响但是多因素表明有影响:一般是出现了共线性,也就是因素A和因素B有相同的变化趋势,但真正影响因变量的只有B,A是一种虚假的相关关系。
解决方法:一般可以进行相关性和共线性分析来解决这一种难题。满足相关性和共线性要求,对传统统计模型的建立十分重要,在建模之前进行这些检验,让变量更符合输入的形式,都可以提升模型的拟合效果。
2、平台操作
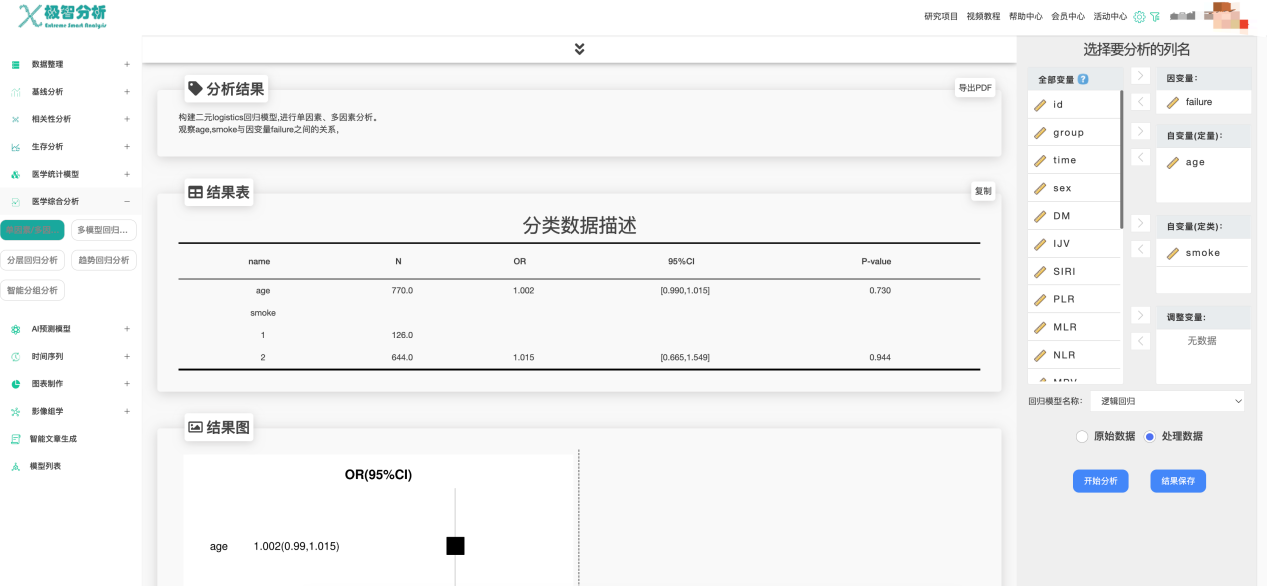
作为模型建立的预处理部分,单/多因素分析,都可以在我们平台轻松地实现,纳入调整变量即可得到多因素结果,具体演示如下
在分析栏选择因变量,自变量,即可得到分析结果,通过OR值、p值和森林图来判断自变量对因变量是否有显著影响。
3、案例分析
这是 Lipids in Health and Disease (IF=3.876)杂志上发表的一篇文章《High lipoprotein(a) concentrations are associated with lower type 2 diabetes risk in the Chinese Han population: a large retrospective cohort study》。这是一项大型回顾性队列研究,研究的是中国汉族人群中高脂蛋白浓度与较低的2型糖尿病风险相关性。
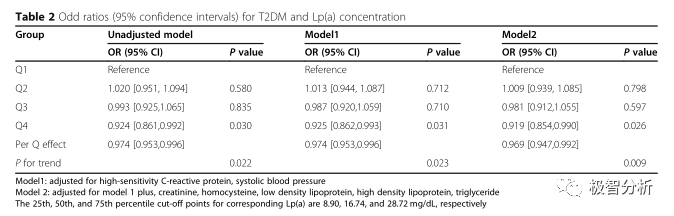
作者将Lp(A)水平按照四分位数进行分组:四分位数1(Q1):0~8.90 mg/dl;四分位数2(Q2):8.90~16.74 mg/dl;四分位数3(Q3):16.74~28.72 mg/dl;四分位数4(Q4):>28.72 mg/dl。
多因素Logistic回归模型用于确定Lp(A)浓度是否与T2DM的发病独立相关。
未调整模型:Lp(A)四分位2-4的OR值和95%CI分别为1.020(0.951,1.094),0.993(0.925,1.065)和0.924(0.861,0.992)。
调整模型1:调整超敏C反应蛋白和收缩压后,结果与未调整组相似[Q4,0.925(0.862,0.993),P=0.031]。
调整模型2:对模型1中包含的因素加上肌酐、同型半胱氨酸、甘油三酯、低密度脂蛋白胆固醇和高密度脂蛋白胆固醇进行调整后,与模型1相似的结果如下:在Q4组中,Lp(A)与T2 DM风险显著相关[0.919(0.854,0.990),P=0.026]。