Development of a Web-Based Model for Predicting Cervical Lymph Node Metastasis in children and adolescents with PTC Using Machine Learning Algorithms
- Project Instruction
- Model Description
- Model Description Figures
- Project Flow Chart
Background
甲状腺癌 (Thyroid cancer, TC) 是最常见的内分泌系统恶性肿瘤,其发病率在世界范围内呈上升趋势。 甲状腺乳头状癌 (PTC) 在儿童和青少年人群中相对少见,但近年来发病率也呈上升趋势。儿童和青少年PTC与成人PTC的临床表现及预后不同。 因此,适用于成年人的治疗模式可能不适用于儿童或青少年。尽管儿童和青少年PTC的长期预后较好,一旦发生颈部淋巴结转移 (CLNM) 则死亡风险显著增加。 目前评价术前淋巴结状态的方法主要有超声检查 (US) 和有创细针穿刺抽吸 (FNA) , 但敏感性有限。目前尚缺乏更准确的方法来识别CLNM的风险。 因此开发新的诊断工具来预测颈部淋巴结状况是非常必要。机器学习 (ML) 是一种新的基于计算机的数据分析方法,已广泛应用于临床医学。 通过从数据集模式学习,ML可以发现更多变量和结果之间的交互作用,这比传统的统计方法要有更好的预测准确性。 由于很少有研究建立基于儿童及青少年PTC患者的颈部淋巴结转移预测模型。 本研究旨在构建基于XGBoost算法的网络可视化在线计算模型,用于识别儿童及青少年PTC患者CLNM的相关危险因素。
Thyroid carcinoma (TC) is the most common endocrine system malignancy, and its incidence is increasing worldwide. Papillary thyroid carcinoma (PTC) is relatively uncommon in children and adolescents, but its incidence has also been increasing in recent years. The clinical manifestations and prognosis of PTC in children and adolescents differ from those in adults. Therefore, a treatment model that works for adults may not work for children or adolescents. Despite the favorable long-term prognosis of PTC, the risk of death increases significantly once lymph node metastasis (LNM) occurs. The current methods for evaluating preoperative lymph node status mainly include ultrasonography and invasive fine-needle aspiration (FNA), but their sensitivity is limited. There is currently a lack of more accurate methods to identify the risk of cervical lymph node metastasis (CLNM). Therefore, it is necessary to develop new diagnostic tools to predict the status of cervical lymph nodes. Machine learning (ML) is a new computer-based data analysis method that has been widely used in clinical medicine. By learning from dataset patterns, ML can discover more interactions between variables and outcomes with better accuracy than traditional statistical methods. Since few studies have established PTC-based CLNM prediction models in children and adolescents. This study aimed to construct a network visualization online computing model based on the XGBoost algorithm to identify the relevant risk factors for CLNM in children and adolescents with PTC.
Parameter Description
Age: 0: ≤10; 1: 11-18
Tumor size: 0: ≤1cm, 1: 1-2cm, 2: 2-4cm, 3:>4cm
Extrathyroidal extension: 0: Intrathyroidal extension or minimal extrathyroidal extension; 1: Gross extrathyroidal extension
Region: 0: Pacific Coast; 1: East; 2: Northern Plains; 3: Southwest
Multifocality: 0: Solitary tumor; 1: Multifocal tumor; 2: Unknown
1.模型介绍:
XGboost (extreme Gradient Boosting) is an
improved algorithm based on the GDBT (Gradient Boosting Decision Tree) algorithm. Traditional
GDBT Model uses only the first derivative in the optimization, but XGBoost preforms the
second-order Taylor expansion of the cost function and adds a regularization item into the cost
function for better performance.As an integrated learning algorithm, it combines the predictions
from an ensemble of weak regression trees, which are added sequentially to the model in order to
maximize predictive performance and minimize model complexity. At the same time, XGboost adds a
complexity control model and learns from random forests to reduce the calculation, making the
model not easy to over-fitting. With above characteristics, XGboost has been draw more attention
for prediction model constructing and risk identification in medical field .
2.样本说明:
共有2323名年龄≤18岁的乳头状甲状腺癌 (PTC) 患者被纳入本项研究。 其中男性受试者412名,女性受试者1911名,发生颈部淋巴结转移 (CLNM) 的患者共有1275名。我们在总样本中随机抽取40%的数据作为测试集 (N=929)。 剩余样本作为训练集和验证集进行10折交叉验证。 该模型在训练集中的AUC=0.723(0.005),在验证集中的AUC=0.681 (0.043),在测试集中的AUC=0.679,准确度=0.636。
A total of 2323 patients with papillary thyroid cancer (PTC) aged≤18 years were included in this study. There were 412 male subjects and 1911 female subjects, and a total of 1275 patients with cervical lymph node metastasis (CLNM). We randomly selected 40% of the data in the total sample as the test set (N=929). The remaining samples were used as training set and validation set for 10-fold cross-validation. The model has AUC=0.723 (0.005) in the training set, AUC=0.681 (0.043) in the validation set, and AUC=0.679 in the test set.
3.模型性能
Training set:
| AUROC (SD) |
Accuracy (SD) |
Sensitivity (SD) |
Specificity (SD) |
PPV (SD) |
NPV (SD) |
F1-score (SD) |
| 0.723(0.005) | 0.658(0.006) | 0.645(0.039) | 0.679(0.038) | 0.715(0.016) | 0.606(0.012) | 0.677(0.017) |
Validation set:
| AUROC (SD) |
Accuracy (SD) |
Sensitivity (SD) |
Specificity (SD) |
PPV (SD) |
NPV (SD) |
F1-score (SD) |
| 0.681(0.043) | 0.629(0.041) | 0.626(0.112) | 0.688(0.127) | 0.687(0.045) | 0.578(0.044) | 0.648(0.070) |
Test set:
| AUROC | Accuracy | Sensitivity | Specificity | PPV | NPV | F1-score |
| 0.679 | 0.635 | 0.585 | 0.705 | 0.662 | 0.601 | 0.621 |






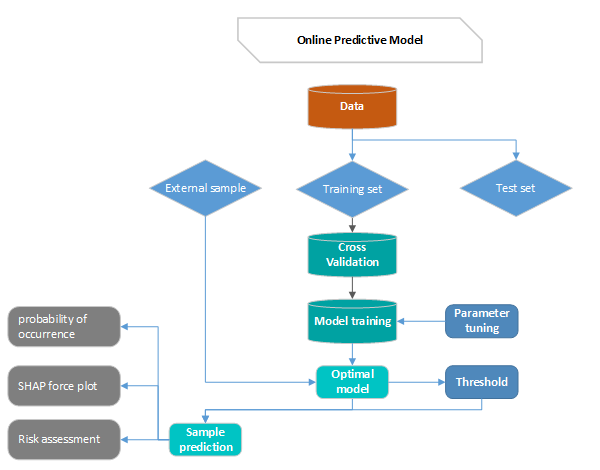
Principle:
First divide the data into training set and test set, then use the cross-validation method to train the model in the training set, train the optimal model as the final model and record the threshold at this time as the final threshold, and finally observe the model in the test performance on the set. By continuously adjusting the parameters of the model, the generalization ability of the model is improved, and the performance of the model in the training set, validation set and test set is relatively optimal.
By the predicted sample into the optimal model, the model will predict the probability of occurrence, generate the SHAP force plot, and then evaluate the risk according to the predicted probability and prediction.
 联系我们:
联系我们: